The Bull Case for the Model Makers
The argument that one or two LLM providers will own the operating system of the world — and that every company, government, and human workflow built on top of them will pay rent to whoever wins.


Stephen Messer, Co-founder of Collective[i] and LinkShare (sold to Rakuten for $425M, 1996–2005). Entrepreneur of the Year. Board member, Spire Global (NYSE: SPIR). Building intelligence.com
Start with the most audacious version of the argument. One company — or at most two — will build an AI system so capable, so embedded in the world's critical infrastructure, and so far ahead of anything else that it becomes the operating system for civilization itself. Every hospital, every bank, every software company, every government will run on it. Every drug discovered, every lawsuit argued, every line of code written will pass through it. The companies currently called Cursor, Harvey, Perplexity — and thousands like them — will be what AOL was to the internet: stepping stones that got people comfortable before the real thing arrived to absorb them. The winner of the large language model race will not be a software company. It will be something closer to a new layer of physics. This is the bull case. It deserves to be taken seriously.
Whether it is correct is a different question, and one this series will examine across three parts. The bear case comes next. The third part offers a prediction — and argues that the real disruption is not the one most people are watching. But first: the bull case, stated as honestly and as completely as possible, because the argument is more coherent than its critics admit.
The Y2K moment nobody is talking about
Before examining the pillars of the bull case individually, there is a forcing-function argument that underlies all of them and that has not received the attention it deserves. It is not about which model is most capable, or which company has the most capital, or which team has the best researchers. It is about what happens to enterprise technology when agents take over — and what that transition does to the question of where organizations live.
The Y2K crisis of 1999 was not primarily a technical problem. It was a migration problem. The underlying issue — two-digit year codes in legacy software — was well understood and fixable. What made it a crisis was the deadline. Every organization, regardless of its preference for deliberation or its institutional resistance to change, had to move by a fixed date. The urgency was not created by the technology. It was created by the calendar. And the urgency compressed a migration that would have taken a decade of normal enterprise sales cycles into roughly eighteen months of frantic, budget-unconstrained action. Vendors who were positioned in that window captured market share they held for the next twenty years.
The agent transition creates a structurally similar moment — but without a fixed calendar date, and with consequences that compound rather than simply expire. When AI agents begin handling not just discrete tasks but continuous workflows — managing a company's customer relationships, running its sales pipeline, handling its legal document review, operating its financial reconciliation — the question of which platform those agents live on stops being a procurement decision and starts being an infrastructure decision. And infrastructure decisions, unlike software purchases, are not easily revisited.
AOL in the mid-1990s was not the best version of the internet. It was a walled garden — curated, controlled, and in many ways technically inferior to the open web that existed alongside it. But for tens of millions of Americans encountering the internet for the first time, AOL was not a compromise. It was the whole thing. The simplicity of a single interface that handled everything — email, news, chat, shopping, search — was worth more than the theoretical freedom of a more open alternative they didn't know how to use.
The agent era is setting up an analogous dynamic. As AI agents proliferate, the complexity of managing agents that span multiple platforms, multiple model providers, multiple security contexts, and multiple data environments will become genuinely intolerable for most enterprises. The IT organization that is currently managing 106 to 275 SaaS applications per company — already a source of documented productivity loss — will face an order-of-magnitude harder problem when those applications each have agents that need to communicate, share context, and hand off tasks to each other. The answer to that complexity is not more integration middleware. It is a closed platform where the agents, the data, the security model, and the intelligence layer are unified from the start.
The company that owns that closed platform owns the AOL moment for AI. And like AOL, it will not need to be technically superior to every open alternative. It will need to be present, complete, and trusted at the exact moment enterprises decide they cannot manage the complexity anymore. That moment is not coming. It is arriving.
Gartner projects that by 2028, AI agents will outnumber human employees in most enterprise organizations — 10 agents for every 1 seller, per their analysis of the sales function alone. Extend that ratio across legal, finance, HR, operations, and customer service, and the implication is that the majority of enterprise workflow will be agent-mediated within a business cycle. Every one of those agents needs to live somewhere. Every one of them needs a model to reason with, a data environment to draw from, a security context to operate within, and a platform to coordinate with other agents. The organization that decides this question does not get to decide it twice. The first decision calculates the switching cost for every subsequent one.
This is the Y2K forcing function. Not a fixed deadline, but a competitive one: the first company in any industry whose agents are running on a unified platform gains a coordination advantage over competitors whose agents are fragmented across providers. That advantage shows up in speed, in data coherence, in the quality of decisions agents make when they can see the full context rather than siloed fragments of it. Once one competitor has that advantage and it becomes visible in their results, every other company in the industry faces a forced migration — not because a date changed, but because standing still became untenable. The urgency is not created by a calendar. It is created by the competitor who moved first.
The bull case argues that this dynamic — enterprises racing to consolidate onto a single agent platform before their competitors do — is the most underappreciated forcing function in the entire AI landscape. It does not require the leading model to be categorically better. It requires it to be present, integrated, and trusted at the moment the migration happens. And whoever owns that moment owns the account for a generation — the same way IBM owned enterprise computing for thirty years not because its technology was always the best, but because it was the safe choice when the decision was made and switching costs did the rest.
The capital aggregation nobody has seen before
The first pillar of the bull case is the sheer scale of capital concentration already underway, which has no precedent in the history of private markets.
OpenAI has raised $110 billion at a $730 billion valuation — the largest private technology financing round ever recorded. Anthropic closed a $30 billion round at $380 billion in February 2026, making it the second-largest. Together, the two pure-play frontier model companies have raised more than $140 billion in the past twelve months alone, at a combined valuation approaching $1.1 trillion. Neither is publicly traded. Neither is profitable. Both are burning more than $5 billion per year.

Add Google's planned $185 billion in capital expenditure for 2026 alone — most of it pointed at AI infrastructure — and the picture comes into focus. The capital flowing into frontier model development is not venture money anymore. It is sovereign-level commitment. SoftBank. Saudi Arabia's Public Investment Fund. Singapore's GIC. Abu Dhabi's MGX. The money is coming from entities that think in decades, not quarters, and that understand that whoever owns the model owns the margin on everything built on top of it.
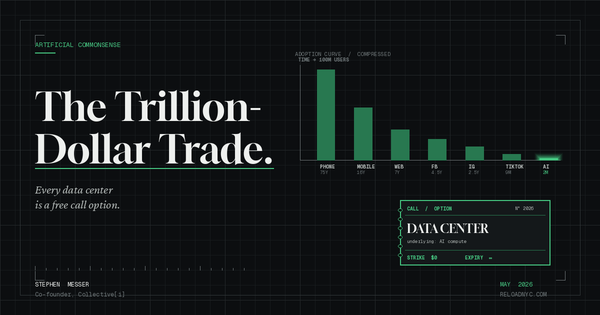
Project Stargate — the joint venture between OpenAI, SoftBank, Oracle, and MGX announced in January 2025 — committed $500 billion over four years, with $100 billion deployed immediately. That is not a product launch. That is an infrastructure buildout of the kind previously associated with interstate highways and nuclear programs. Seven gigawatts of planned data center capacity. OpenAI's own projections call for revenue exceeding $280 billion annually by 2030 and 44% of the world's adult population using its services in some form. These numbers may be fantasy. But the capital being raised to pursue them is real, and it is compounding in ways that make it structurally difficult for latecomers to catch up.
This is the first thing the bull case requires you to believe: that capital at this scale, concentrated this quickly, in a technology with these cost dynamics, creates a lead that is not just large but self-reinforcing. More capital buys more compute. More compute trains better models. Better models attract more users and revenue. More revenue raises more capital at higher valuations. The loop is not broken by incremental competition. It is broken only by a fundamental shift in the nature of the technology — which is precisely what the bear case will argue. But within the model paradigm as it currently exists, the capital dynamic favors concentration.
Talent: the other scarce resource
Capital is necessary but not sufficient. The second pillar is talent, and it is arguably the more durable moat — because capital can be raised, but the people who understand how to train frontier models at the highest level of capability cannot be manufactured on demand.
The pool of researchers who have actually built and trained a frontier large language model is measured in the hundreds globally. Not thousands. Not tens of thousands. Hundreds. And that number includes the people at the major labs, the people who left to found competitors, and the people at the handful of academic institutions doing work at the relevant level. The implication is stark: the companies that currently hold the most capable models also hold most of the people who know how to build them. This creates a compounding advantage that looks less like a software moat and more like the concentration of nuclear expertise in the 1940s — a domain where the knowledge itself is the barrier.
The talent flows confirm it. When Anthropic was founded in 2021, it was by eleven former OpenAI researchers, including Dario Amodei, who had been VP of Research. When Mira Murati left OpenAI in 2024, her new company raised a $2 billion seed round — the largest ever recorded — before it had built anything, purely on the belief that she could build something frontier. Safe Superintelligence, founded by Ilya Sutskever, raised at a $32 billion valuation with no product. The market is pricing individual researchers with frontier model experience at valuations that have no parallel in any previous technology wave. That is the market's assessment of how scarce and how consequential this talent actually is.
Clayton Christensen's classic argument is that incumbents are disrupted by companies that can move fast because they have nothing to protect. In the LLM race, that logic runs in reverse — and it is one of the strongest arguments in the bull case.
Google invented the transformer architecture that powers all of these models, published in 2017. Google had AlphaGo, DeepMind, and the largest AI research organization in the world. Google had more data, more compute, and more talent than any competitor. And yet OpenAI launched ChatGPT in November 2022 and captured a market that Google had every advantage to own. Why? Because Google had $200 billion per year in search and advertising revenue that a truly better AI answer engine would cannibalize. The same technology that Google invented was used by a company with nothing to lose to eat into Google's most valuable business. The Innovator's Dilemma worked against the incumbent with the most to protect.
The bull case argues this same dynamic now works for the leading frontier labs — because they have already committed to a trajectory so radical that they cannot afford to slow down. OpenAI's $600 billion compute commitment is not just a bet. It is a strategic lock-in that makes incremental thinking structurally impossible. When you have promised SoftBank and the Saudi sovereign wealth fund that you are building the operating system of the world, you cannot pivot to building a better productivity suite. The brakes are removed. That is, in the bull case, a feature rather than a bug.
The monetization model nobody has built yet
Before asking whether the LLM winners can monetize their lead, it is worth getting the history of the last technology that created a trillion-dollar company from a position of search dominance exactly right — because the actual history is more instructive than the version that gets told.
Google's PageRank was genuinely better than what came before. AltaVista, Ask Jeeves, Yahoo Search — the prior generation of search engines were being gamed by SEO manipulation into producing increasingly irrelevant results. PageRank solved that. But PageRank did not make Google a trillion-dollar company. What made Google a trillion-dollar company was a monetization model it did not invent.
The keyword auction — the mechanism by which advertisers bid against each other for placement next to specific search terms, paying only when a user clicks — was invented by Bill Gross at GoTo.com, later renamed Overture. Google's AdWords was a direct adaptation of that model. The legal system agreed: Google settled with Yahoo (which had acquired Overture) for $270 million in stock in 2004, just before Google's IPO. AdSense, which placed contextually matched ads across third-party websites and paid publishers a share of the revenue, was structurally identical to the affiliate marketing model that LinkShare had pioneered in 1996 — performance-based distribution, tracked by click, paid on outcome. Neither the auction nor the affiliate model originated at Google. What Google did was recognize that both models, applied to its search dominance and scaled through its infrastructure, would generate margins unlike anything in the history of advertising.
By 2023, that insight was worth $175 billion in search revenue and $31 billion from the network — more than 80% of Alphabet's total revenue from a monetization layer that had nothing to do with the quality of the underlying algorithm. The algorithm attracted users. The auction extracted value from their attention at a margin that approached 100% at the incremental unit. The cash that generated funded Maps, Gmail, Android, YouTube, Cloud, and everything else. The advertising flywheel built the rest of the company.
The current monetization model for frontier AI — token pricing — has a structural flaw that the GoTo/AdWords history illuminates directly. Token pricing treats all compute as equivalent. A poem costs the same per token as a drug discovery query. A customer service response costs the same per token as a legal brief that will be filed in federal court. The input determines the price, not the value of the output to the person receiving it.
The keyword auction solved exactly this problem in search. GoTo recognized that the word "mesothelioma" — typed by someone researching a lawsuit — was worth orders of magnitude more to an advertiser than the word "weather." The auction let the market set that price dynamically. Advertisers bid what the traffic was worth to them, not what it cost Google to serve it. The margin on a high-intent commercial keyword was structurally different from the margin on an informational query, and the auction made that difference visible and capturable.
No LLM provider has built this model yet. The company that figures out how to price AI output by the value it creates — drug discovery queries priced against the $2.8 billion cost of traditional development, legal brief queries priced against the billable hours they replace, financial model queries priced against the alpha they generate — rather than the compute it consumes, has found the AdWords of AI. That company does not need to have invented the best model. It needs to have invented the right auction. The upside that token pricing is leaving on the table is, by any reasonable estimate, enormous. The bull case requires believing someone will claim it. It does not yet tell us who.
The Uber comparison — and where it breaks
The other profitability model the bull case points to is Uber, which burned billions in losses for more than a decade before becoming GAAP profitable in 2023. The Uber playbook: subsidize both sides of the marketplace — riders and drivers — with investor capital until network density makes the unit economics work, then raise the take rate once no competitor can replicate the density. By 2024, Uber had $44 billion in annual gross bookings, $12 billion in revenue, and demonstrated operating leverage: each incremental trip contributed substantially to profit rather than to fixed cost coverage. The bet on density paid off. The question is whether the same bet translates.
There are genuine parallels. Both involve massive early losses in pursuit of network effects. Both require concentration — Uber needs density in a given city; an LLM provider needs training data, user feedback, and API integrations at scale. Both benefit from switching costs that increase with dependency. And crucially, both can raise take rates once the alternative disappears: Uber's average fare is 52% higher than in 2019, and riders are still riding.
But the Uber analogy has limits the bull case must reckon with. Uber's moat has physical and regulatory dimensions that LLMs lack. A competitor cannot instantly replicate the 7.8 million drivers in Uber's network. They cannot Vibe-code their way to geographic density. The friction is structural. In the LLM space, the equivalent is less clear — DeepSeek trained a model comparable to OpenAI's O1 for $5.9 million, against OpenAI's reported $100 million-plus training cost for the same capability level. If training costs can be compressed by an order of magnitude by a well-funded competitor, the moat looks different than Uber's. The bull case requires believing that capability leads compound faster than cost curves fall — a claim that is empirically contested.
What the players actually look like right now
The bull case is not abstract. There are specific companies with specific positions, and the competitive landscape is already concentrating.
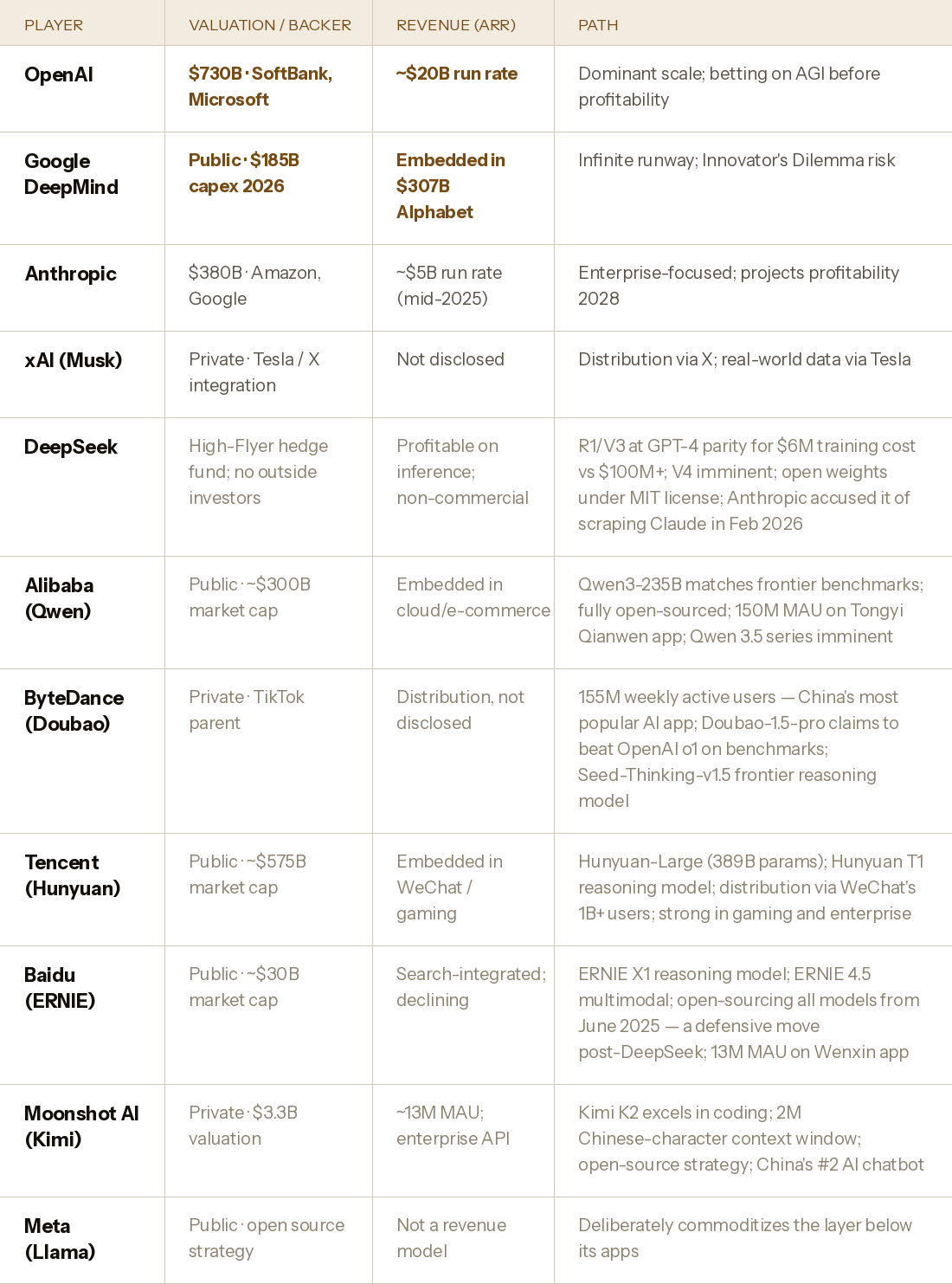
The consolidation logic is already visible among the Western players. In 2021, there were dozens of credible frontier model efforts. Today, the capital and talent required to train at the frontier level has concentrated the serious competition to three or four companies. The rest are building on top of those players' APIs — which is precisely the wrapper-company dynamic the bull case predicts will ultimately be absorbed. Cursor, at a $29 billion valuation with $500 million in ARR, is an impressive business. It is also, in the bull case's logic, a business that exists at the pleasure of the model providers whose capabilities it packages. When OpenAI launched Codex and Anthropic extended Claude Code, they were not just releasing products. They were serving notice.
The China picture requires separate analysis — and it is more complex than either "China wins" or "US export controls hold." China invested ¥890 billion ($125 billion) in AI in 2025, representing 38% of global AI investment. Chinese models now run at one-sixth to one-fourth the cost of comparable American systems, per a RAND report published in early 2026. DeepSeek's R1 model — trained for $6 million against OpenAI's reported $100 million for comparable capability — triggered $593 billion in single-day losses from Nvidia's market cap in January 2025 and forced every major Chinese tech company to cut its AI pricing. The immediate strategic response: Alibaba open-sourced Qwen entirely, Baidu committed to open-sourcing ERNIE, ByteDance embraced open weights for Doubao. China is executing what amounts to a deliberate commoditization strategy for the model layer — not because open source is ideologically appealing, but because it neutralizes the US capital advantage at the frontier while deploying distribution advantages (WeChat at 1 billion users, Douyin at 600 million daily actives, Taobao at 500 million users) that Western models cannot replicate. The bull case must account for a world in which the Chinese players do not try to win the model war by the same rules — they change the game.
The vertical integration question
The most aggressive version of the bull case argues that the frontier model winner will not stop at providing intelligence as a service. It will vertically integrate into every high-value domain where that intelligence creates disproportionate returns — and it will do so in ways that make the Google Maps / Gmail / Chrome ecosystem look modest.
Consider what a superintelligent model, if it exists, would be worth in specific contexts. A drug discovery AI that finds compounds in 18 months that previously took 15 years is not a tool. It is a pharmaceutical company. An AI that manages a hedge fund's trading with better signal-to-noise than any human analyst is not a service provider to Citadel. It is a competitor to Citadel. An AI that writes, directs, and distributes entertainment at the quality level of a major studio with a fraction of the cost does not support Disney. It threatens Disney. The bull case argues that the frontier model winner will recognize these opportunities — and that the same intelligence advantage that makes them useful as a tool makes them devastating as a competitor.
This is not speculation about the distant future. OpenAI has already moved into hardware (the Jony Ive device project, the $6.5 billion acquisition of io), robotics research, and web browsers (Atlas). The Sora video generation app — launched in September 2025 — was shut down this week, on March 24, 2026, after downloads fell 75% from their November peak. OpenAI's statement was instructive: the Sora research team would continue, but focused on "world simulation research to advance robotics." Video generation as a consumer product was a side quest. World models as infrastructure for physical AI is the actual bet. The pattern is the same one Google ran from 2004 to 2014: move fast into adjacencies, kill what doesn't compound, double down on what does. The Sora shutdown is not a retreat. It is a resource reallocation into the vertical that matters more.
The bull case is not that one company gets lucky. It is that the economics of intelligence — unlike the economics of most prior technologies — favor concentration rather than diffusion, because the marginal cost of deploying a better model approaches zero while the cost of training it approaches hundreds of billions. That asymmetry, if it holds, produces winner-take-most dynamics that would make Google's dominance look like a competitive market.
Built or bought — and why the question misses the point
There is a habit in technology analysis of asking whether a dominant company was built through genuine innovation or through acquisition and distribution muscle. The question is usually posed as a distinction. The history of platform monopolies suggests it is not.
Microsoft did not become the most valuable company of the 1990s because Windows was the most technically sophisticated operating system. It became dominant because IBM put it on every personal computer in the early 1980s, and that installed base made every software developer write for Windows, which made Windows more valuable, which made more hardware run it. The compounding was distribution-led. The innovation followed the distribution. Then, with the cash that monopoly generated, Microsoft bought or neutralized every meaningful challenger — buying Hotmail to enter email, buying LinkedIn for $26 billion, buying GitHub for $7.5 billion, and eventually investing $13 billion into OpenAI, placing itself at the center of the next platform before the transition was complete. Microsoft did not invent most of what it owns. It bought an early lead and used that lead to buy the next one.
Salesforce ran the same playbook in enterprise software. Marc Benioff did not invent CRM. Siebel Systems did. What Salesforce invented was the delivery model — cloud-based, subscription, no installation — and then used the early mover advantage in that model to acquire Tableau ($15.7 billion), MuleSoft ($6.5 billion), Slack ($27.7 billion), and a dozen others. Each acquisition pushed more products to the same enterprise clients, deepening lock-in, expanding the contract value per customer, and raising the switching cost for anyone considering leaving. By the time a competitor could replicate any individual Salesforce product, Salesforce had already sold five adjacent products to the same buyer. The moat was not the CRM. It was the account.
Google's acquisition record tells the same story at a different scale. Android was bought, not built — $50 million in 2005, before smartphones were a mainstream market, specifically to prevent a competitor from owning the mobile operating system. YouTube was bought for $1.65 billion in 2006 when it had almost no revenue, because Google understood that the winner of online video would own the next layer of advertising inventory. DoubleClick, acquired for $3.1 billion in 2007, gave Google control of the advertising infrastructure that sat between brands and the open web. Waze, for $966 million in 2013, consolidated navigation data that would otherwise have been owned by someone else. In each case, the acquisition was not about the product. It was about eliminating a future competitor while the existing revenue base made the price trivial.
The consolidation strategy has three stages, and all three require being the leader first. Stage one — distribution advantage: an early lead in users, integrations, or enterprise contracts creates a baseline that is expensive for customers to abandon and expensive for competitors to replicate. Security clearances alone take 18 months to obtain; government AI contracts that require cleared infrastructure lock out any model that hasn't already done the work. Stage two — acquisition: the cash and high-valuation stock generated by early leadership makes acquisitions that would be impossible for a challenger trivially affordable for the leader. Buy the models that are closing the capability gap. Buy the distribution channels that would otherwise become competitors. Buy the data sets that would feed a rival. Stage three — margin expansion: each acquisition adds products sold to the same enterprise clients, increasing revenue per account, increasing switching costs, and compressing the ROI calculation that a competitor needs to justify displacing you. Lock-in is not a feature. It is a compounding process that the leader experiences as normal business and the challenger experiences as an insurmountable barrier.
The specific dynamics of AI make this playbook potentially more powerful than in any prior technology wave. Security clearance requirements for government and defense contracts take time that cannot be bought — only accumulated. The time required to pass a hospital system's data privacy review, a bank's vendor risk management process, or a defense contractor's security audit is measured in months to years, not weeks. Every month that the leading model is embedded in enterprise workflows is a month of institutional inertia that a challenger has to overcome, not just a month of capability gap to close. The early lead does not just buy time. It buys the organizational processes, the security certifications, the compliance documentation, and the human relationships that make switching genuinely costly regardless of what the competing model can do.
And when a challenger does emerge with a capability worth worrying about — the bull case argues — the leader buys it. This is not speculation. OpenAI has already made its largest acquisition ever, the $6.5 billion purchase of hardware startup io. Microsoft's $13 billion investment in OpenAI was not a bet on a startup. It was Microsoft's acquisition of the platform layer it did not own — the same move it made with DOS in 1981. The currency for these acquisitions is the high-valuation equity that comes from being the perceived leader. DeepSeek cannot buy the company that threatens to unseat it. The leader can. That asymmetry persists as long as the valuation premium persists.
The path to a trillion-dollar model company
What would it actually take? The arithmetic is straightforward, even if the execution is not. A trillion-dollar AI company — on a reasonable 20x revenue multiple — requires $50 billion in annual revenue. OpenAI projects $280 billion by 2030 on its own internal models. Even discounting that projection heavily, $50 billion is reachable if three conditions hold: the leading model maintains capability differentiation sufficient to command premium pricing; token pricing scales with enterprise adoption rather than commoditizing under competition; and the company successfully expands into enough adjacent verticals to avoid dependence on any single revenue category.
The monetization insight is critical here. Google did not achieve $175 billion in search advertising revenue by charging per search. It scaled an auction — invented by someone else — that made advertisers compete against each other based on the market value of their desired audience, not the cost of serving it. The equivalent for an LLM provider is not token pricing. Token pricing is the API version of charging per search: it prices the input, not the output's value. The real monetization model — the one that would generate AdWords-level margins — prices AI output by what it is worth to the person receiving it. A drug company pays for a molecular discovery query based on what that discovery is worth in its pipeline. A law firm pays for a brief-drafting query based on the billable hours it replaces. A hedge fund pays for a financial modeling query based on the alpha it generates. The winner builds the auction, not just the model.
Lock-in is the other element. Enterprise software companies trade at premium multiples not because their products are irreplaceable on day one, but because switching costs compound over time. The more deeply an organization's workflows are built on a specific model's capabilities, the more expensive it becomes to switch — not because the model is legally exclusive, but because the training, the integrations, the institutional knowledge built around how to get the most out of a specific model, accumulates in ways that are not easily transferred. This is what Microsoft understood about Office and Windows. It is what Salesforce understood about CRM. An enterprise that has rebuilt its entire revenue operation on Collective[i] Intelligence does not switch to a generic alternative because a slightly cheaper option appears. The same logic applies to a hospital system, a law firm, or a financial institution that has rebuilt critical workflows on a specific frontier model.
The honest limits of the bull case
A bull case presented without its own limits is advocacy, not analysis. Three challenges are real and cannot be dismissed.
The first is the cost structure. OpenAI is projected to lose $14 billion in 2026 on approximately $13 billion in revenue. HSBC's analysts estimate the company needs $207 billion in additional capital raises to fund its growth plans through 2030 — after already raising more than any private technology company in history. The unit economics are not converging on profitability at the pace the valuations imply. Inference costs have not fallen as quickly as proponents projected. DeepSeek's ability to achieve comparable capability at a fraction of the training cost is a direct challenge to the assumption that scale is the primary driver of capability. If training cost curves fall faster than the lead compounds, the moat thins.
The second is the commodity risk. Every model claiming differentiation is competing against open-source alternatives — Meta's Llama, Mistral, and a growing number of models that are free to run and improving at pace. The bull case requires that frontier capability — the gap between the best proprietary model and the best open-source alternative — remains large enough to justify the pricing premium. That gap has been real, but it has also been consistently narrowing. A world in which open-source models are 80% as capable as proprietary ones for 0% of the cost is a very different market than the one the bull case assumes.
The third is the question the next two parts of this series will examine directly: whether the LLM paradigm is actually the path to superintelligence at all — or whether the real disruption is coming from a different direction entirely. The models being built today are extraordinarily capable at language tasks. They are not, at present, capable of the kind of embodied, physical-world reasoning that would make them genuinely able to run a drug company, manage a physical supply chain, or design a building that needs to stand up. That gap matters. The bull case implicitly assumes it closes. Whether and how is not yet settled science.
The bull case, stated plainly: one or two frontier model companies will establish a capability and capital lead so large that it becomes self-sustaining; will use that lead — and the high-valuation equity it generates — to acquire every meaningful challenger before it can scale; will find the monetization equivalent of AdWords that converts intelligence dominance into margin dominance; will vertically integrate into the highest-value domains where that intelligence creates competitive advantage; and will emerge as companies worth multiples of any technology company that has existed before.
None of those four things is unprecedented. Microsoft did all of them. Google did all of them. Salesforce did most of them. What is unprecedented is the speed and scale at which the AI version is happening — and the degree to which the winner's advantage in each dimension feeds the others. Capital buys talent. Talent builds capability. Capability attracts distribution. Distribution generates revenue. Revenue funds acquisitions. Acquisitions extend the lead. The bull case is that this loop, once established at frontier scale, does not break easily.
The case is coherent. The capital is real. The talent concentration is real. The distribution lock-in is accumulating right now, contract by contract, security clearance by security clearance. Whether the monetization layer materializes, whether the cost curves move in the right direction, and whether the LLM paradigm is actually the path to the intelligence that would justify the valuations — those are the questions the next two parts of this series will work through.
The bull case deserves to be taken seriously. It also deserves scrutiny.
These ideas deserve more than a comment section.
Connect, push back, or share a perspective at intelligence.com — a professional network built for exactly this kind of exchange.
Sources & data
- OpenAI $14B projected 2026 loss on ~$13B revenue — Fortune, November 2025; HSBC $207B additional capital estimate
- Anthropic $5.6B 2024 loss — The Information
- Sam Altman "saturated the chat use case" — CNBC, mid-2025
- HEC Paris "well-kept secret" — HEC Dare, 2025
- LeCun, AMI Labs, $1B raise at $3.5B valuation — CNBC, Let's Data Science, March 2026; LeCun quote from public lecture, November 2025
- Fei-Fei Li, World Labs, $230M, Marble — TechCrunch, November 2025
- Ilya Sutskever, Safe Superintelligence, $32B valuation — public reporting
- DeepSeek R1 $6M training vs $100M+ — multiple sources, January 2025; $593B Nvidia market cap loss — public market data
- ChatGPT traffic share 87% to 65%, 2025 — Similarweb
- Pentagon/ChatGPT uninstalls 295% spike — Indagari data, TechCrunch, March 2026
- Google TurboQuant: 6x memory compression, 8x H100 speedup, zero accuracy loss — ICLR 2026, published March 25, 2026; memory chip stock drops 5–7% — Tom's Hardware, Winbuzzer, Help Net Security, March 2026
- NVIDIA KVTC: 20x compression at <1% accuracy penalty — ICLR 2026, Winbuzzer
- DeepSeek-OCR: 7–20x token reduction via visual tokens, 97% accuracy at <10x compression — Tom's Hardware, Fortune, DigitalOcean, October 2025
- OpenClaw OAuth ban — Anthropic, January 2026; DHH quote, HN 245+ points — community reporting; Peter Steinberger hired by OpenAI — PCWorld, The New Stack, February–March 2026
- Airline value chain margins — BCG aerospace analysis; Umbrex aviation industry research
- Token price compression 99.7% — NavyaAI cost report, February 2026; Andreessen Horowitz 10x/year inference cost decline
- OpenClaw 250,000+ GitHub stars — Tenten, March 2026
- OpenClaw routing: 65–70% to cheaper models — community benchmarks
- Claude Max/Pro rate limits — Anthropic documentation; developer community reporting, February 2026