The Bear Case for the Model Makers
Among the first AI models to achieve mass acceptance — language models, diffusion models — were systems built on the one input every lab in the world has equal access to: the public internet. Commodity data in. Commodity output out.


Stephen Messer, Co-founder of Collective[i] and LinkShare (sold to Rakuten for $425M, 1996–2005). Entrepreneur of the Year. Board member, Spire Global (NYSE: SPIR). Building intelligence.com
This piece is not a bear case on AI. It is a bear case on a specific business model — one I'll call the Commodity Intelligence Problem: when the input to an AI system is universally available, the output cannot sustain a price premium, regardless of how impressive that output is. This is not a criticism of the technology. It is a description of the economics. And it is the one structural argument that is almost entirely absent from the current conversation about AI valuations.
LLMs and diffusion models — among the first AI models to reach mass acceptance — were trained on the public internet. Every book, article, forum post, image, and piece of code that humans had produced and made publicly available. That data was not proprietary to any one lab. It was equally available to OpenAI, Anthropic, Google, Meta, Mistral, DeepSeek, Alibaba, ByteDance, and every graduate student with a GPU cluster. When the training input is a commodity — when every competitor starts from the same raw material — the output is a commodity too. Steel is a commodity. Corn is a commodity. Both are extraordinarily useful. Neither generates software-company margins for the companies that produce them.
This explains something the revenue growth charts obscure: why did five major labs all ship models of roughly equivalent capability within months of each other, despite wildly different capital bases, team sizes, and starting positions? Because they were all distilling the same underlying resource. The differentiation that existed — GPT-4 vs. Claude 2 vs. Gemini — was real but incremental, the way one refinery's gasoline is slightly different from another's. Not different enough to command a lasting price premium. Not different enough to prevent the commodity floor from arriving.
I have spent thirty years building businesses at the intersection of data and commerce — from affiliate marketing at LinkShare to economic intelligence at Collective[i]. The pattern I keep seeing in the current AI market is one I recognize: extraordinary products, misplaced assumptions about where the margin settles. The people getting the margin in AI are not who the headlines suggest. What follows is the argument for why, starting with what's already known and ending with what the financial models don't yet account for.
The known bear case — arguments already in circulation

These arguments are real. They are also already priced into the market's skepticism. What they don't fully capture is the structural position problem — the question of who, in the AI value chain, actually gets the margin. That is the argument that hasn't been made clearly.
The new bear case — arguments we think are underweighted

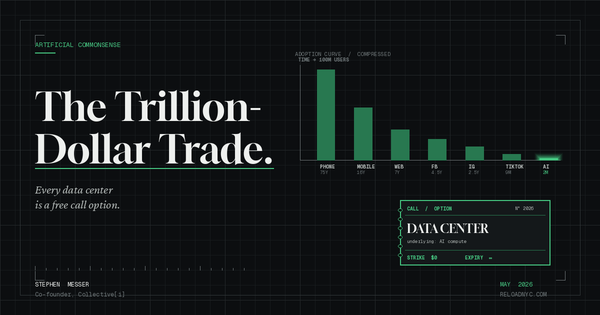
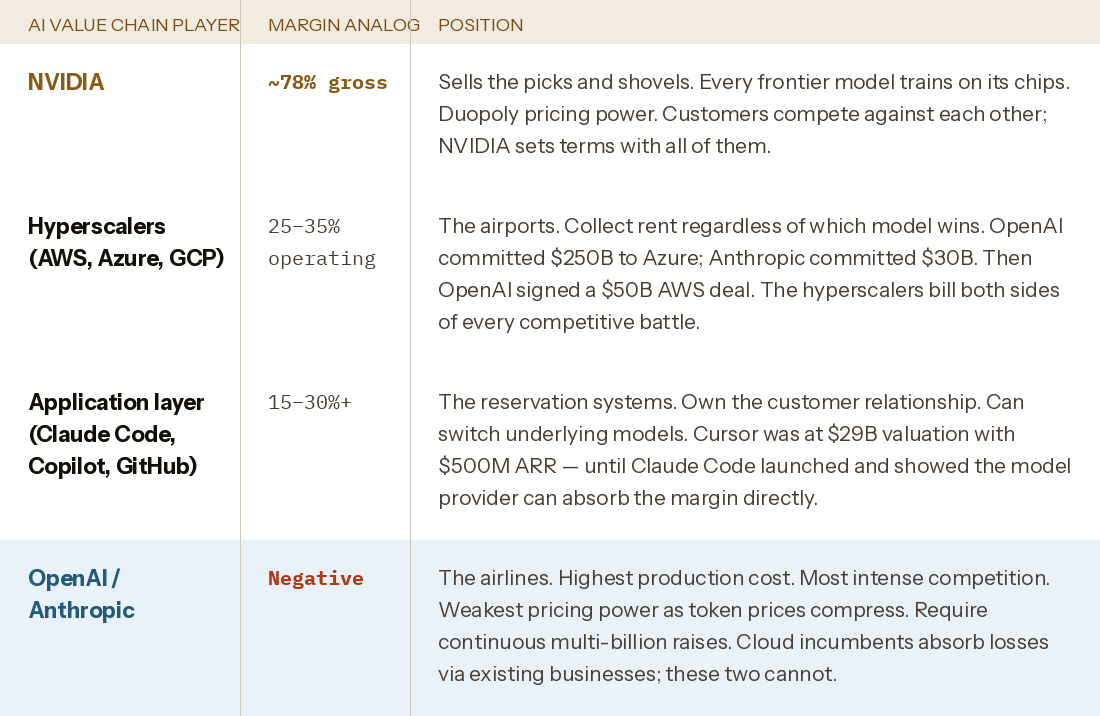
The value chain map
The airline analogy is not rhetorical. It is a documented structural phenomenon across every capital-intensive technology industry. The company operating the transformative service is rarely the company capturing the margin.
The token price treadmill — documented
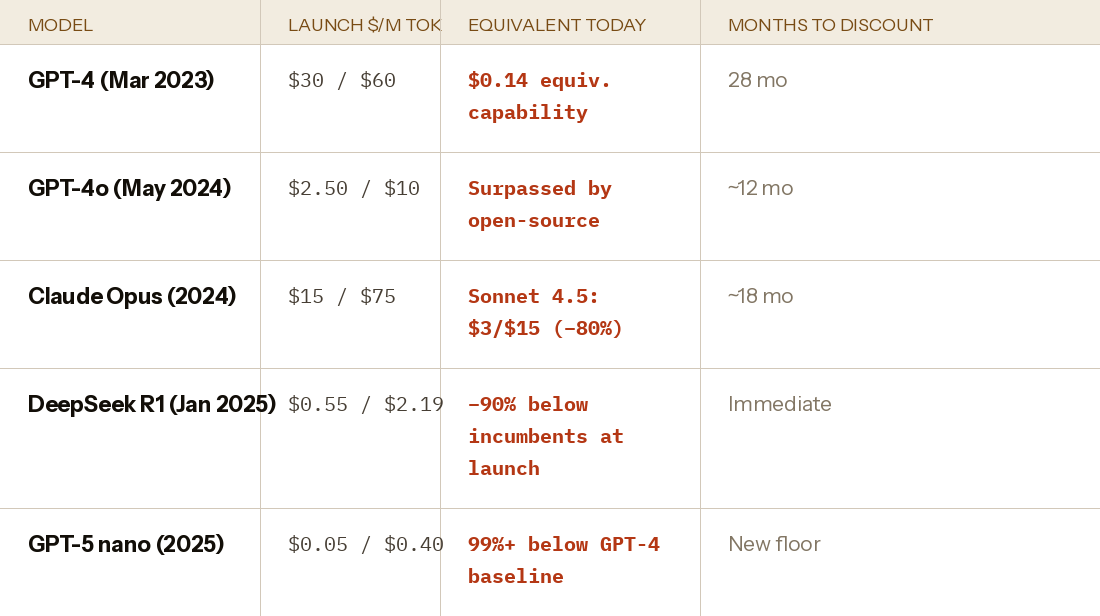
Andreessen Horowitz documented inference costs declining approximately 10x per year at fixed capability. The commodity floor does not reverse. Each efficiency innovation — TurboQuant (6x memory compression, zero accuracy loss), KVTC (20x compression), MoE architectures, DeepSeek-OCR (7–20x token reduction for documents) — reduces the cost of serving intelligence before the training investment in the next frontier model can be recovered.
The efficiency innovation signal
The most important development of the past two weeks has received almost no financial analysis. On March 25, 2026, Google published TurboQuant — a training-free algorithm that compresses LLM key-value cache memory by 6x with zero accuracy loss and delivers up to 8x attention speedup on H100 GPUs. The paper was accepted at ICLR 2026. Independent developers built working implementations within 24 hours of the publication. Memory chip stocks fell 5–7% the next day.
The market reaction was immediate and pointed: if frontier models can run on one-sixth the memory with no performance penalty, the capital investment thesis for massive data center buildouts — the core of the bull case's infrastructure moat — shifts. NVIDIA's rival KVTC method achieves 20x compression. Both are heading to production tooling in Q2 2026.
Separately, DeepSeek's OCR model compresses documents by converting text to visual tokens — achieving 97% fidelity at 10x compression, with some workloads at 20x. A 1,000-word document that previously required ~1,000 tokens can be processed with ~100 vision tokens. The implication is not just cheaper document processing. It is that the fundamental token pricing model — which bills by input/output count — becomes increasingly disconnected from the computational work actually performed. When a document can be processed for 1/10th the tokens, the revenue per query falls proportionally.
These are not incremental improvements. They are signals that the people who built the models are now optimizing for efficiency — which only makes economic sense if you believe raw capability scaling has run out of room. When capability improvements slow, cost reduction becomes the competitive lever. Cost reduction is good for users and catastrophic for frontier margin.
The bull case requires: (1) frontier capability remains meaningfully differentiated, (2) token prices stabilize or rise, (3) users cannot route around frontier models for most workloads. Model what happens if each assumption fails at 50% probability:
Scenario A — capability plateau firms up (50% weight): If frontier-to-previous-generation performance gaps compress further, the user who pays $200/month for Max has less justification for the premium. Developers on OpenClaw already report routing 65–70% of tasks to DeepSeek/Gemini at 90% lower cost with no quality degradation. If that routing share reaches 80% as efficiency techniques diffuse, addressable frontier revenue shrinks by ~60%. A company projecting $280B in 2030 revenue at today's model mix sees that estimate compress to $110B — still large, but not at 50x multiples.
Scenario B — inference efficiency neutralizes infrastructure moat (65% weight): TurboQuant and KVTC reduce memory requirements by 6–20x. If production adoption follows the 90-day community implementation pace, a model that required 8x H100s now runs on 1–2. DeepSeek's training cost innovations diffuse. The capex advantage of owning the largest data center narrows. At $600B committed compute spend by 2030, even a 30% reduction in required infrastructure per unit of capability represents $180B of misallocated capital. The model providers pay the bill; the hyperscalers keep the revenue.
Scenario C — user routing arbitrage reaches scale (70% weight): OpenClaw currently has 250,000+ GitHub stars and derivatives globally. At current adoption rates, by end of 2026 the routing framework pattern is embedded in millions of developer workflows. If frontier models compete for only 20–30% of queries (the portion requiring genuine top-tier reasoning), and open-source handles the rest, blended revenue per user falls 50–70% even if frontier prices hold. This is not hypothetical — it is already happening at current enterprise scale.
None of these scenarios requires AI to fail. They require only that the business model assumption — that the model provider captures proportional value from AI adoption — proves incorrect. If any two of these three scenarios materialize, the current valuations require a growth and margin trajectory that no software company in history has sustained.
The OpenClaw OAuth episode — the competitive dynamics in miniature
The OAuth episode is worth examining in detail because it illustrates the structural problem in concentrated form. OpenClaw users discovered that by extracting an OAuth token from their $200/month Claude Max subscription and feeding it to OpenClaw, they could run agentic workloads that would cost $1,000+ in direct API billing — a 5x arbitrage on flat-rate pricing. Users were consuming millions of tokens per afternoon session through autonomous agents that didn't exist when the pricing model was designed.
Anthropic banned the practice in January 2026. The developer community reaction was intense: DHH called it "very customer hostile," the Hacker News thread generated 245+ points, GitHub Issues received 147+ reactions. Anthropic reversed some bans, then updated its Terms of Service. The situation resolved in a way that illustrates the competitive bind precisely: Peter Steinberger, OpenClaw's creator, was hired by OpenAI. OpenAI explicitly kept OAuth open for OpenClaw users. The community documentation for migrating from Anthropic to OpenAI for OpenClaw workflows multiplied overnight. The article from users who chose not to move back was titled: "The era of using Claude Max via OAuth with third-party tools is ending."
One measure to protect margin. One exodus of developers to the competitor. One community perception shift. The rate limit equivalent plays out the same way: Claude's 5-hour rolling windows and 7-day caps force developers to other providers during resets, where they discover the alternatives are adequate, and where they reduce their Anthropic dependency on the next billing cycle. Every measure to protect revenue per user is simultaneously a lesson in how to need less of your product.
Words are not intelligence — and the market will eventually notice
There is an argument at the bottom of the bear case that requires honesty about using these systems at scale. LLMs are extraordinary pattern-matchers. They are not, in any meaningful technical sense, intelligent. The gap between fluency and understanding is real, and anyone who has pushed these systems on complex multi-step reasoning, novel planning, or physical-world causality has encountered it. LeCun's formulation is precise: "An LLM doesn't understand that if you push a glass off a table, it will break. It only knows that the words 'glass' and 'break' often appear together in that context."
The financial consequence: the tasks where LLMs would generate the most revenue — autonomous drug discovery, genuinely novel code architecture, legal strategy, medical diagnosis — are precisely the tasks where the architecture most frequently produces confident-sounding hallucinations. Enterprises discovering this at scale are building human review layers into workflows that were supposed to be autonomous. That is not a $280B-per-year revenue trajectory. It is a productivity tool at software margins.
The Commodity Intelligence Problem, in short: when the training input is equally available to every competitor, the output converges, the pricing compresses, and the margin flows upstream — to NVIDIA, to the hyperscalers, to the application layer. Not to the model providers bearing the training cost.
AI is not a bad business. LLMs trained on commodity data, sold at compressing margins, against open-source alternatives built from the same training corpus, are a bad business. The distinction is the entire argument.
The bull case requires believing that one company achieves a capability lead so durable it breaks the commodity dynamic. That is possible. It has not happened in three years of trying. The efficiency innovations arriving weekly suggest the window is narrowing, not widening.
Airlines move 4.7 billion people a year. Every airport knows this and prices accordingly. The airline makes 2 cents on the dollar in a good year.
AOL had 35 million subscribers when the browser arrived. It was a real company. It is gone.
These ideas deserve more than a comment section.
Connect, push back, or share a perspective at intelligence.com — a professional network built for exactly this kind of exchange.
Sources & data
OpenAI $14B projected 2026 loss on ~$13B revenue: Fortune, November 2025; HSBC $207B additional capital estimate · Anthropic $5.6B 2024 loss: The Information · Sam Altman "saturated the chat use case": CNBC, mid-2025 · HEC Paris "well-kept secret": HEC Dare, 2025 · LeCun, AMI Labs, $1B raise at $3.5B: CNBC, Let's Data Science, March 2026; LeCun quote from public lecture November 2025 · Fei-Fei Li, World Labs, $230M, Marble: TechCrunch, November 2025 · Ilya Sutskever, Safe Superintelligence, $32B valuation: public reporting · DeepSeek R1 $6M training vs $100M+: multiple, January 2025; $593B Nvidia market cap loss: public market data · ChatGPT traffic 87% to 65%, 2025: Similarweb · Pentagon/ChatGPT uninstalls 295%: Indagari data, TechCrunch, March 2026 · Google TurboQuant: 6x memory compression, 8x H100 speedup, zero accuracy loss, published March 25 2026, ICLR 2026; memory chip stock drops 5–7%: Tom's Hardware, Winbuzzer, Help Net Security, March 2026 · NVIDIA KVTC: 20x compression at <1% accuracy penalty, ICLR 2026: Winbuzzer · DeepSeek-OCR: 7–20x token reduction via visual tokens, 97% accuracy at <10x compression: Tom's Hardware, Fortune, DigitalOcean, October 2025 · OpenClaw OAuth ban: Anthropic January 2026; DHH quote, HN 245+ points: community reporting; Peter Steinberger hired by OpenAI: PCWorld, The New Stack, February–March 2026 · Airline value chain margins: BCG aerospace analysis; Umbrex aviation industry research · Token price compression 99.7%: NavyaAI cost report, February 2026; Andreessen Horowitz 10x/year inference cost decline · OpenClaw 250,000+ GitHub stars: Tenten, March 2026 · OpenClaw routing: 65–70% to cheaper models per community benchmarks · Claude Max/Pro rate limits: Anthropic documentation; developer community reporting, February 2026